14 Graphing with ggplot2
For this chapter you’ll need the following file, which is available for download here: apparent_per_capita_alcohol_consumption.rda.
We’ve made some simple graphs earlier; in this lesson we will use the package ggplot2 to make simple and elegant-looking graphs.
The “gg” part of ggplot2 stands for “grammar of graphics”, which is the idea that most graphs can be made using the same few “pieces.” We’ll get into those pieces during this lesson. For a useful cheat sheet for this package see here.
install.packages("ggplot2")library(ggplot2)
# Warning: package 'ggplot2' was built under R version 4.2.2When working with new data, it’s often useful to quickly graph the data to try to understand what you’re working with. It is also useful when understanding how much to trust the data.
The data we will work on is data about alcohol consumption in US states from 1977-2017 from the National Institutes of Health. It contains the per capita alcohol consumption for each state for every year. Their method to determine per capita consumption is amount of alcohol sold / number of people aged 14+ living in the state. More details on the data are available here.
Now we need to load the data.
load("data/apparent_per_capita_alcohol_consumption.rda")The name of the data is quite long so for convenience let’s copy it to a new object with a better name, alcohol.
alcohol <- apparent_per_capita_alcohol_consumptionThe original data has every state, region, and the US as a whole. For this lesson we’re using data subsetted to just include states. For now let’s just look at Pennsylvania.
penn_alcohol <- alcohol[alcohol$state == "pennsylvania", ]14.1 What does the data look like?
Before graphing, it’s helpful to see what the data includes. An important thing to check is what variables are available and what the units are for these variables.
head(penn_alcohol)
# state year ethanol_beer_gallons_per_capita
# 1559 pennsylvania 2017 1.29
# 1560 pennsylvania 2016 1.31
# 1561 pennsylvania 2015 1.31
# 1562 pennsylvania 2014 1.32
# 1563 pennsylvania 2013 1.34
# 1564 pennsylvania 2012 1.36
# ethanol_wine_gallons_per_capita ethanol_spirit_gallons_per_capita
# 1559 0.33 0.71
# 1560 0.33 0.72
# 1561 0.32 0.70
# 1562 0.32 0.70
# 1563 0.31 0.68
# 1564 0.31 0.67
# ethanol_all_drinks_gallons_per_capita number_of_beers
# 1559 2.34 305.7778
# 1560 2.36 310.5185
# 1561 2.33 310.5185
# 1562 2.34 312.8889
# 1563 2.33 317.6296
# 1564 2.34 322.3704
# number_of_glasses_wine number_of_shots_liquor number_of_drinks_total
# 1559 65.48837 147.4128 499.2000
# 1560 65.48837 149.4891 503.4667
# 1561 63.50388 145.3366 497.0667
# 1562 63.50388 145.3366 499.2000
# 1563 61.51938 141.1841 497.0667
# 1564 61.51938 139.1079 499.2000So each row of the data is a single year of data for Pennsylvania. It includes alcohol consumption for wine, liquor, beer, and total drinks - both as gallons of ethanol (a hard unit to interpret) and more traditional measures such as glasses of wine or number of beers. The original data only included the gallons of ethanol data, which I converted to the more understandable units. If you encounter data with odd units, it is a good idea to convert it to something easier to understand - especially if you intend to show someone else the data or results.
14.2 Graphing data
To make a plot using ggplot() (please note that the function does not have a 2 at the end of it, only the package name does), all you need to do is specify the data set and the variables you want to plot. From there you add on pieces of the graph using the + symbol (which operates like a dplyr pipe) and then specify what you want added.
For ggplot() we need to specify four things:
- The data set
- The x-axis variable
- The y-axis variable
- The type of graph - e.g. line, point, etc.
Some useful types of graphs are:
geom_point()- A point graph, can be used for scatter plotsgeom_line()- A line graphgeom_bar()- A barplotgeom_smooth()- Adds a regression line to the graph
14.3 Time-series plots
Let’s start with a time-series of beer consumption in Pennsylvania. In time-series plots the x-axis is always the time variable while the y-axis is the variable whose trend over time is what we’re interested in. When you see a graph showing, for example, crime rates over time, this is the type of graph you’re looking at.
The code below starts by writing our data set name. Then says what our x- and y-axis variables are called. The x- and y-axis variables are within parentheses of the function called aes(). aes() stands for aesthetic, and what’s included inside here describes how the graph will look. It’s not intuitive to remember, but you need to include it. Like in dplyr functions, you do not need to put the column names in quotes or repeat which data set you are using.
ggplot(penn_alcohol, aes(x = year,
y = number_of_beers))
Note that on the x-axis it prints out every single year and makes it completely unreadable. That is because the “year” column is a character type, so R thinks each year is its own category. It prints every single year because it thinks we want every category shown. To fix this, we can make the column numeric, and ggplot() will be smarter about printing fewer years.
penn_alcohol$year <- as.numeric(penn_alcohol$year)ggplot(penn_alcohol, aes(x = year,
y = number_of_beers))
When we run it, we get our graph. It includes the variable names for each axis and shows the range of data through the tick marks. What is missing is the actual data. For that we need to specify what type of graph it is. We literally add it with the + followed by the type of graph we want. Make sure that the + is at the end of a line, not the start of one. Starting a line with the + will not work.
Let’s start with point and line graphs.
ggplot(penn_alcohol, aes(x = year,
y = number_of_beers)) +
geom_point()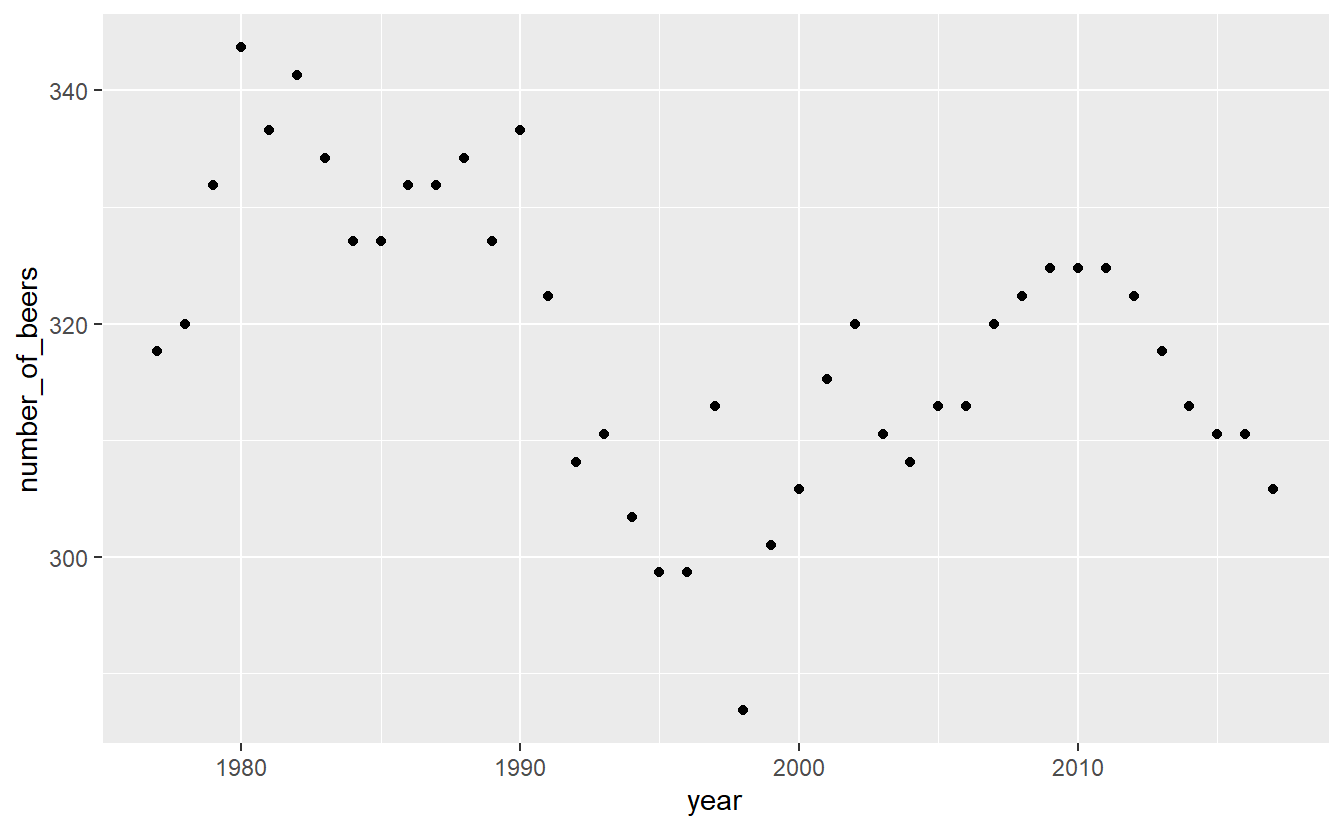
ggplot(penn_alcohol, aes(x = year,
y = number_of_beers)) +
geom_line()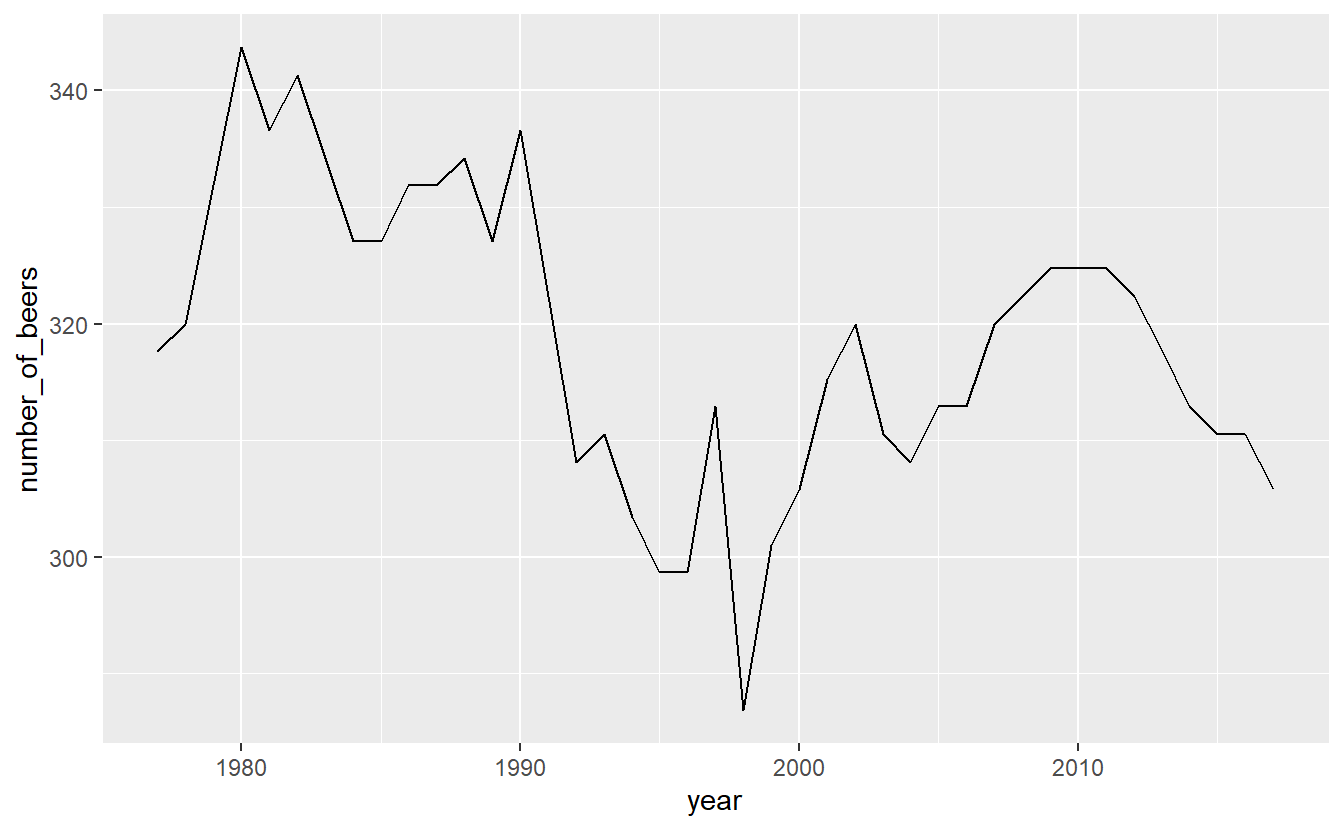
We can also combine different types of graphs.
ggplot(penn_alcohol, aes(x = year,
y = number_of_beers)) +
geom_point() +
geom_line()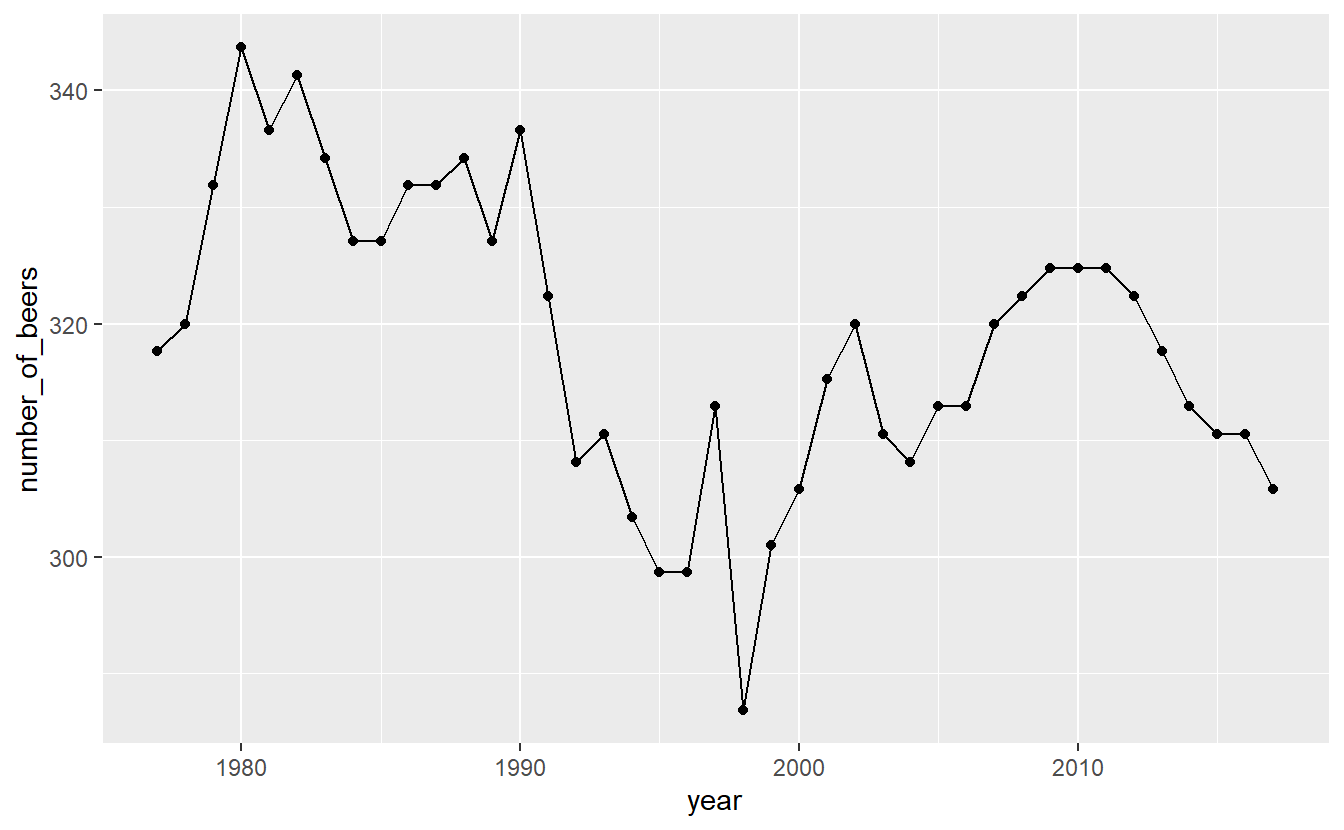
It looks like there’s a huge change in beer consumption over time. But look at where they y-axis starts. It starts around 280 so really that change is only ~60 beers. That’s because when graphs don’t start at 0, it can make small changes appear big. We can fix this by forcing the y-axis to begin at 0. We can add expand_limits(y = 0) to the graph to say that the value 0 must always appear on the y-axis, even if no data is close to that value.
ggplot(penn_alcohol, aes(x = year,
y = number_of_beers)) +
geom_point() +
geom_line() +
expand_limits(y = 0)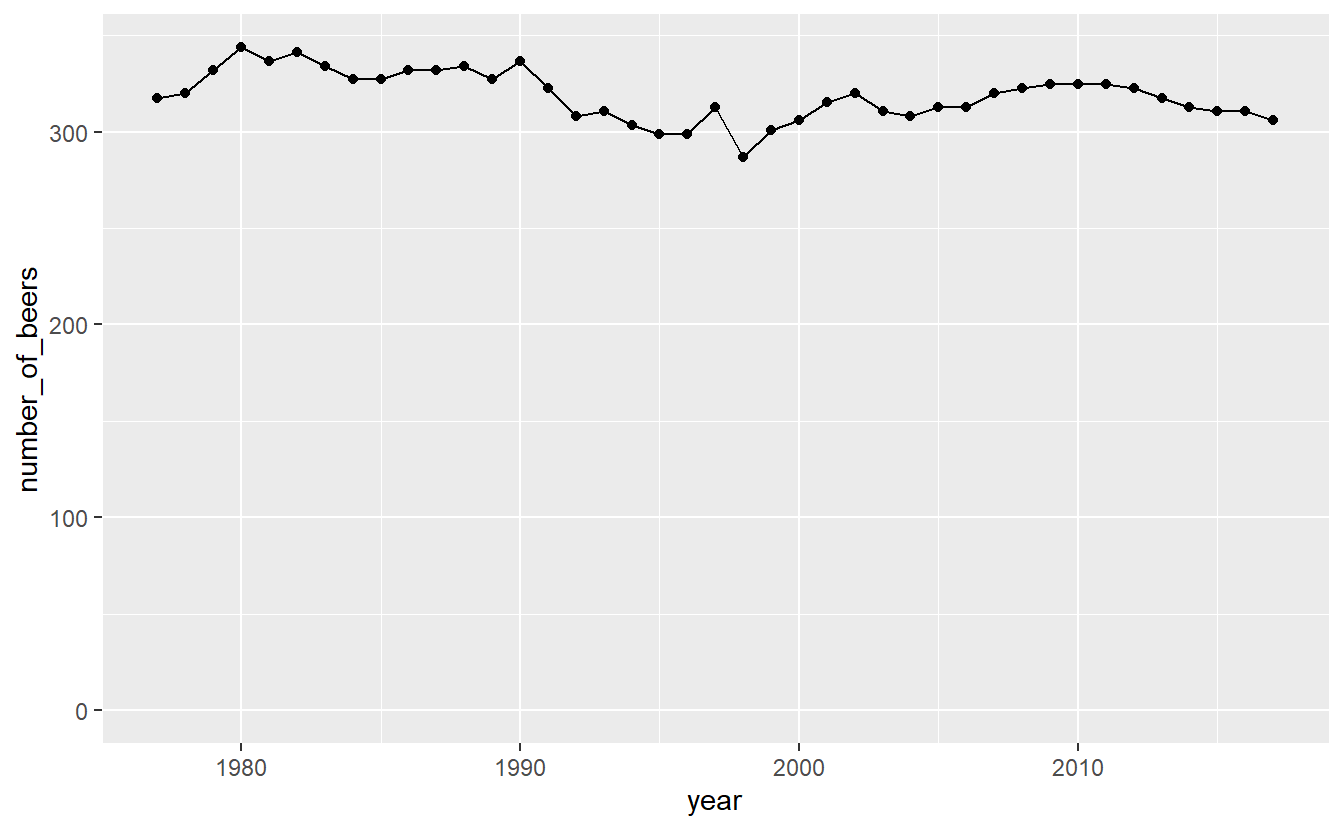
Now that graph shows what looks like nearly no change even though that is also not true. Which graph is best? It’s hard to say.
Inside the types of graphs we can change how it is displayed. As with using plot(), we can specify the color and size of our lines or points.
ggplot(penn_alcohol, aes(x = year,
y = number_of_beers)) +
geom_line(color = "forestgreen", size = 1.3)
# Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
# ℹ Please use `linewidth` instead.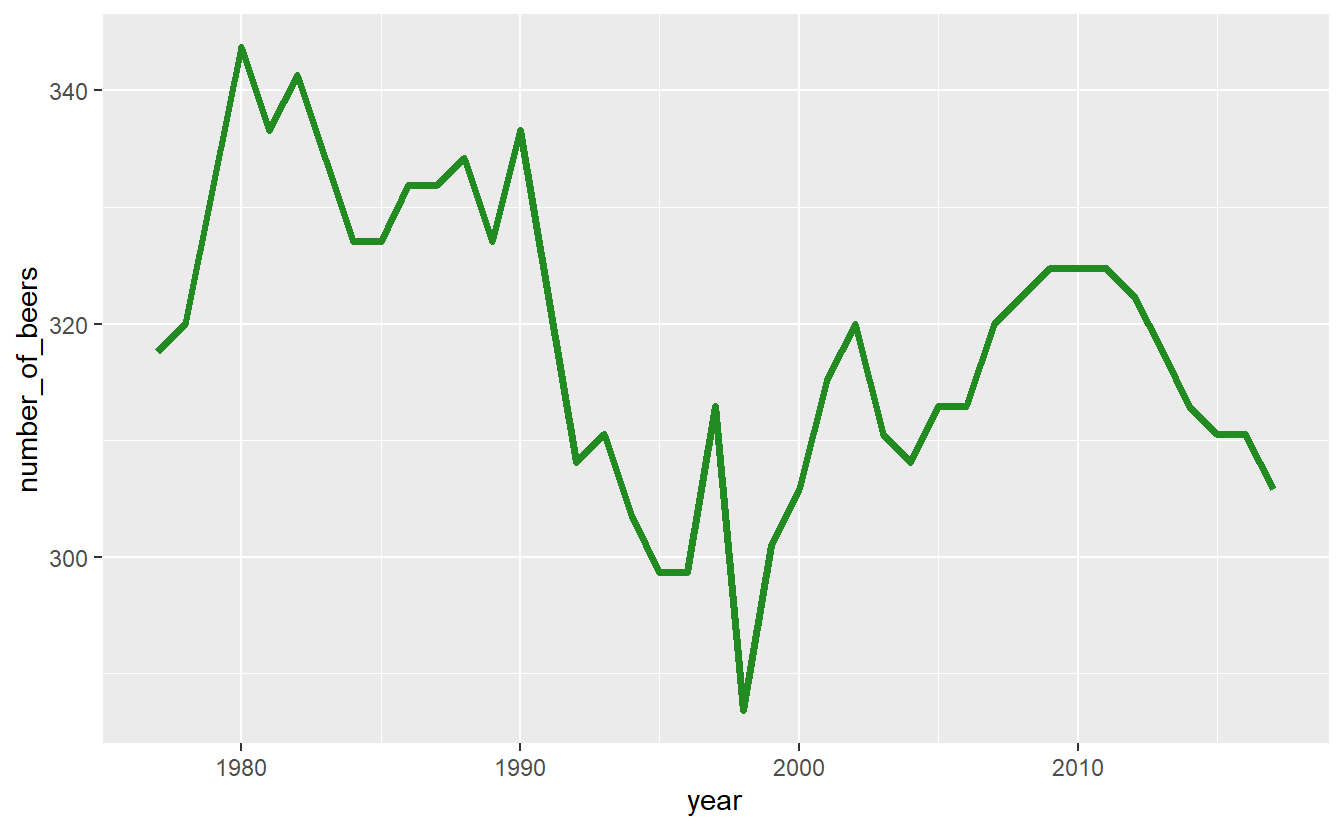
Some other useful features are changing the axis labels and the graph title. Unlike in plot() we do not include it in the () of ggplot() but use their own functions to add them to the graph. The input to each of these functions is a string for what we want it to say.
xlab()- x-axis labelylab()- y-axis labelggtitle()- graph title
ggplot(penn_alcohol, aes(x = year,
y = number_of_beers)) +
geom_line(color = "forestgreen", size = 1.3) +
xlab("Year") +
ylab("Number of Beers") +
ggtitle("PA Annual Beer Consumption Per Capita (1977-2017)")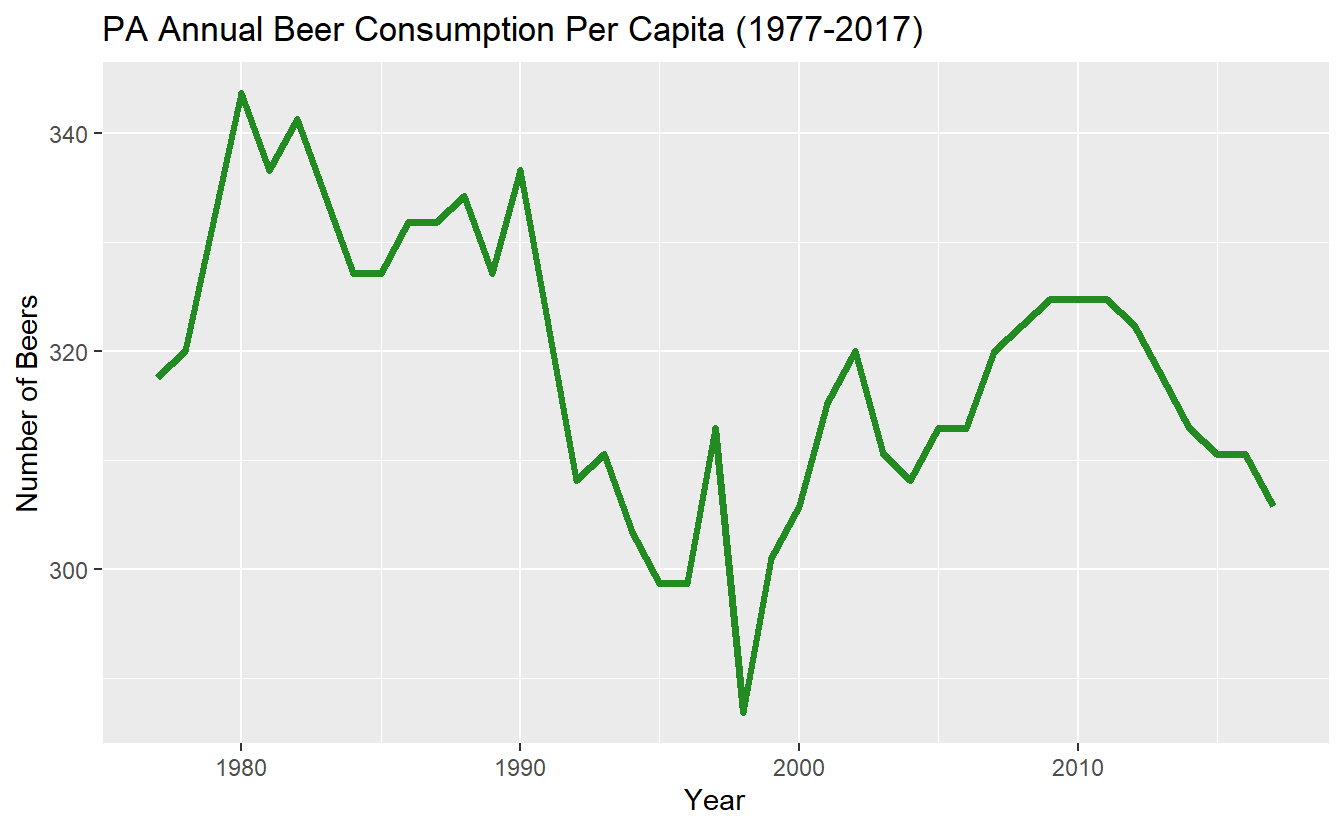
Many time-series plots show multiple variables over the same time period (e.g. murder and robbery over time). There are ways to change the data itself to make creating graphs like this easier, but let’s stick with the data we currently have and just change ggplot().
Start with a normal line graph, this time looking at wine.
ggplot(penn_alcohol, aes(x = year,
y = number_of_glasses_wine)) +
geom_line()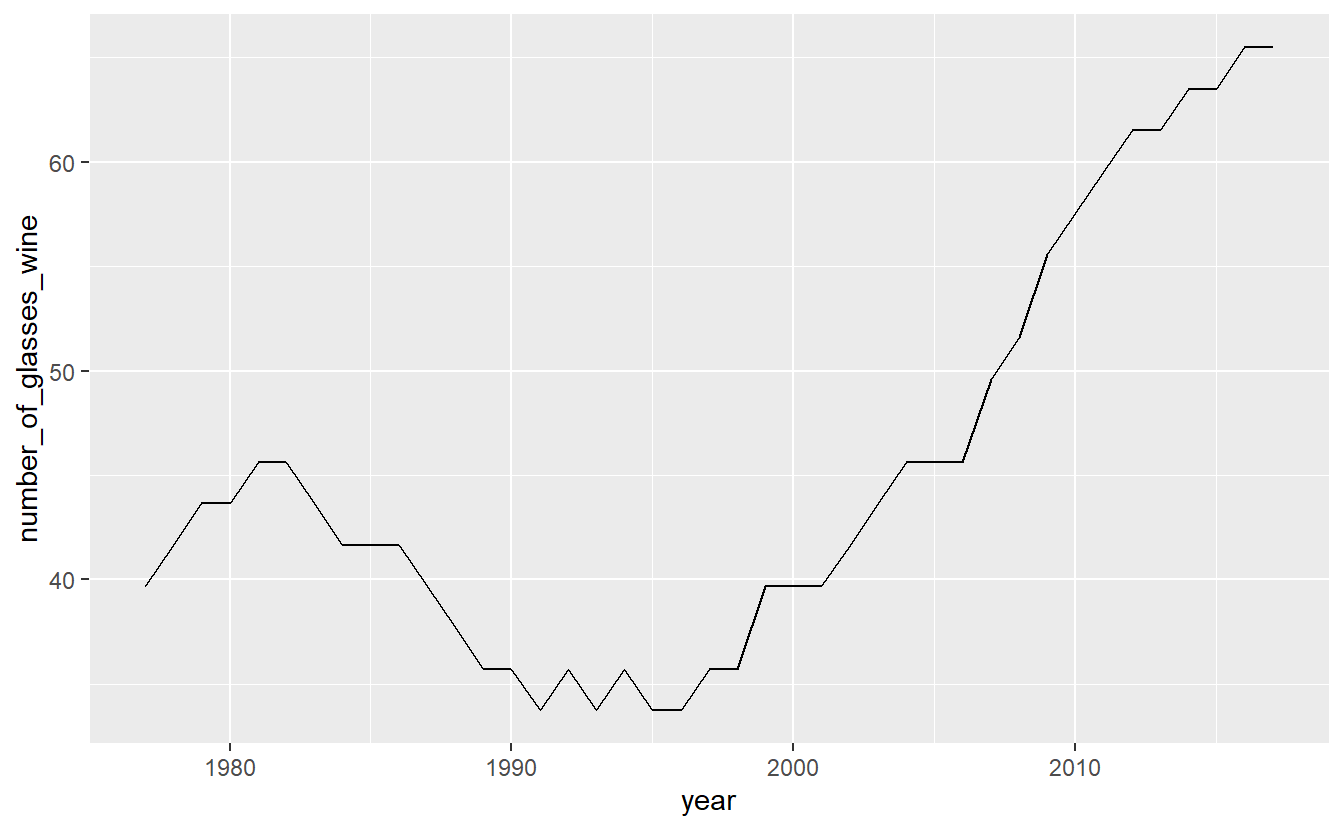
Then include a second geom_line() with its own aes() for the second variable. Since we are using the penn_alcohol data set for both lines we do not need to include it in the second geom_line() as it assumes that the data is the same if we don’t specify otherwise. If we used a different data set for the second line, we would need to specify which data set it is inside of geom_line() and before aes().
ggplot(penn_alcohol, aes(x = year,
y = number_of_glasses_wine)) +
geom_line() +
geom_line(aes(x = year,
y = number_of_shots_liquor))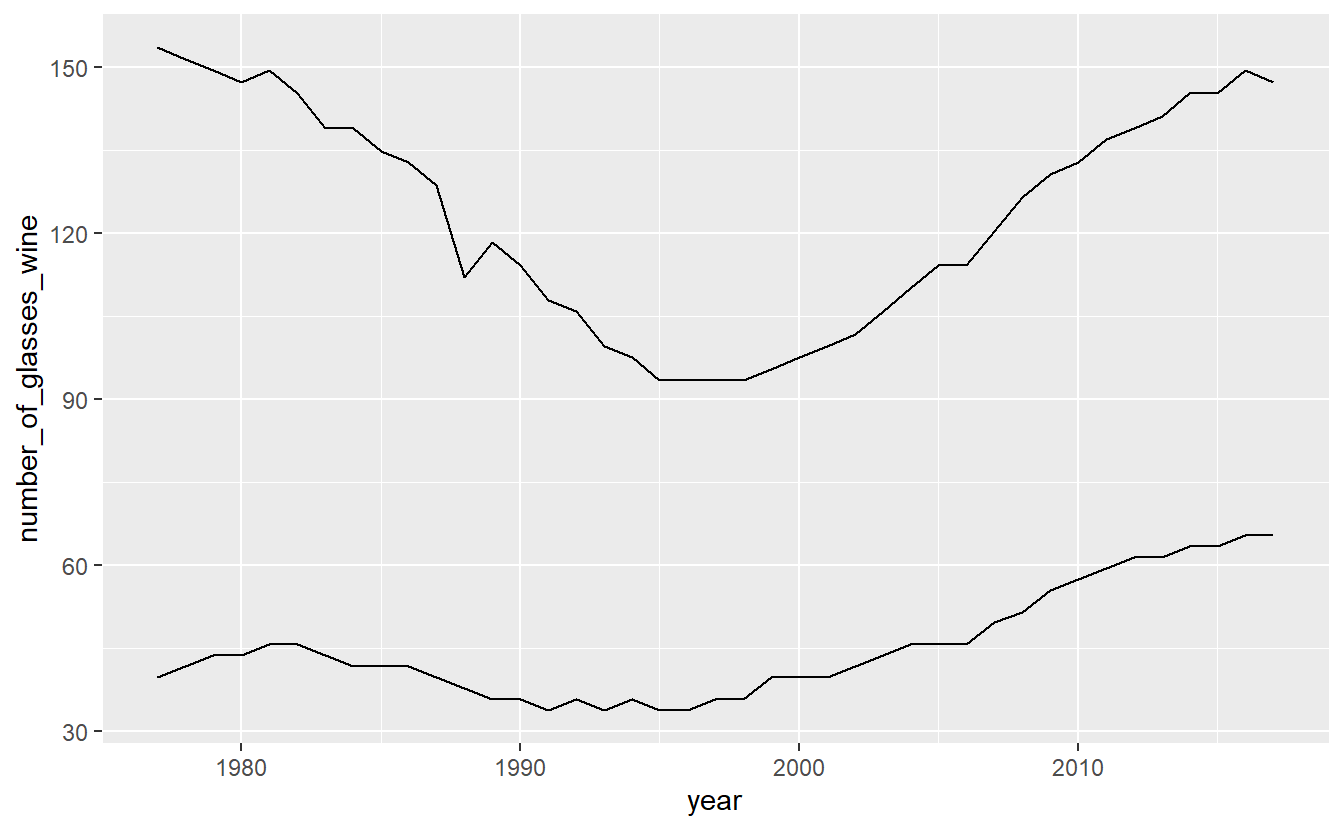
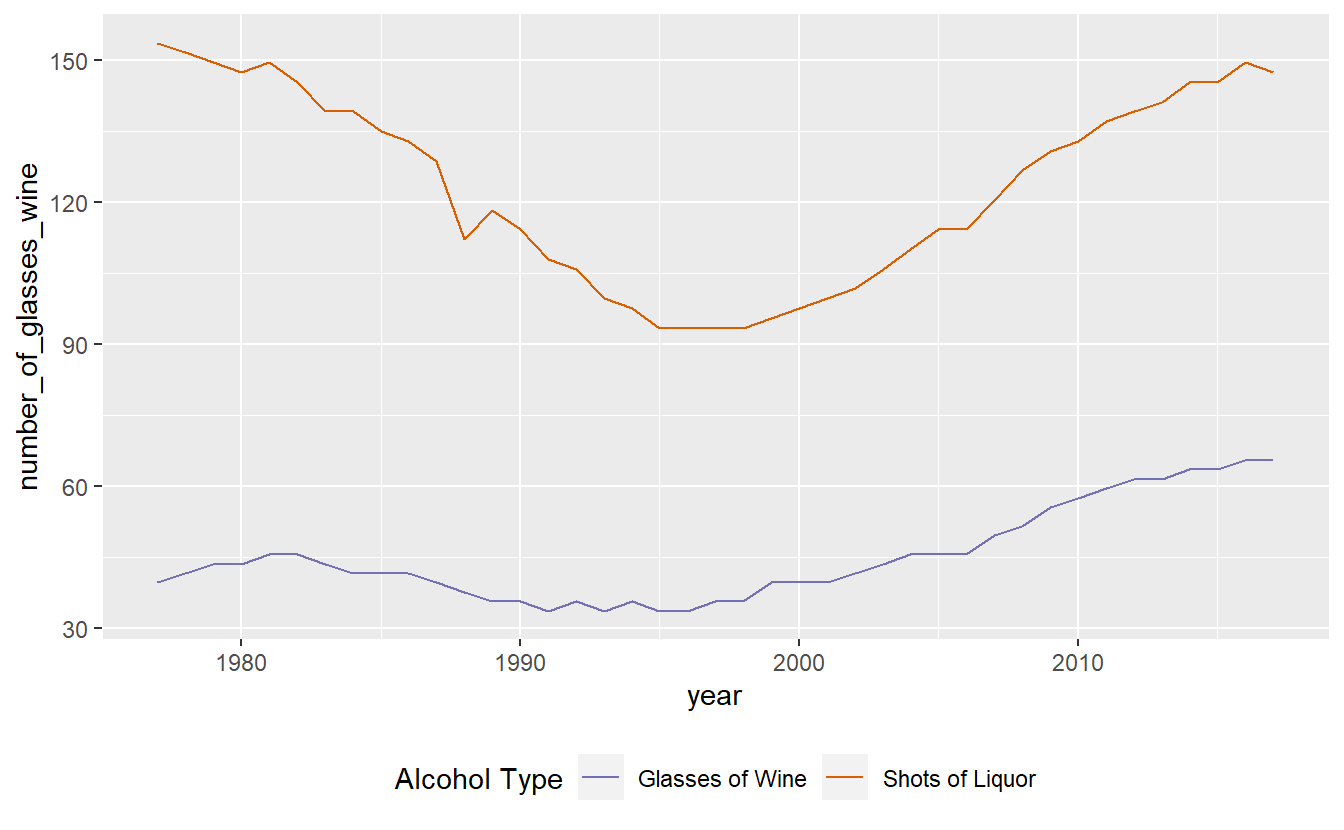
A problem with this is that both lines are the same color. We need to set a color for each line and do so within aes(). Instead of providing a color name, we need to provide the name the color will have in the legend. Do so for both lines.
ggplot(penn_alcohol, aes(x = year,
y = number_of_glasses_wine,
color = "Glasses of Wine")) +
geom_line() +
geom_line(aes(x = year,
y = number_of_shots_liquor,
color = "Shots of Liquor"))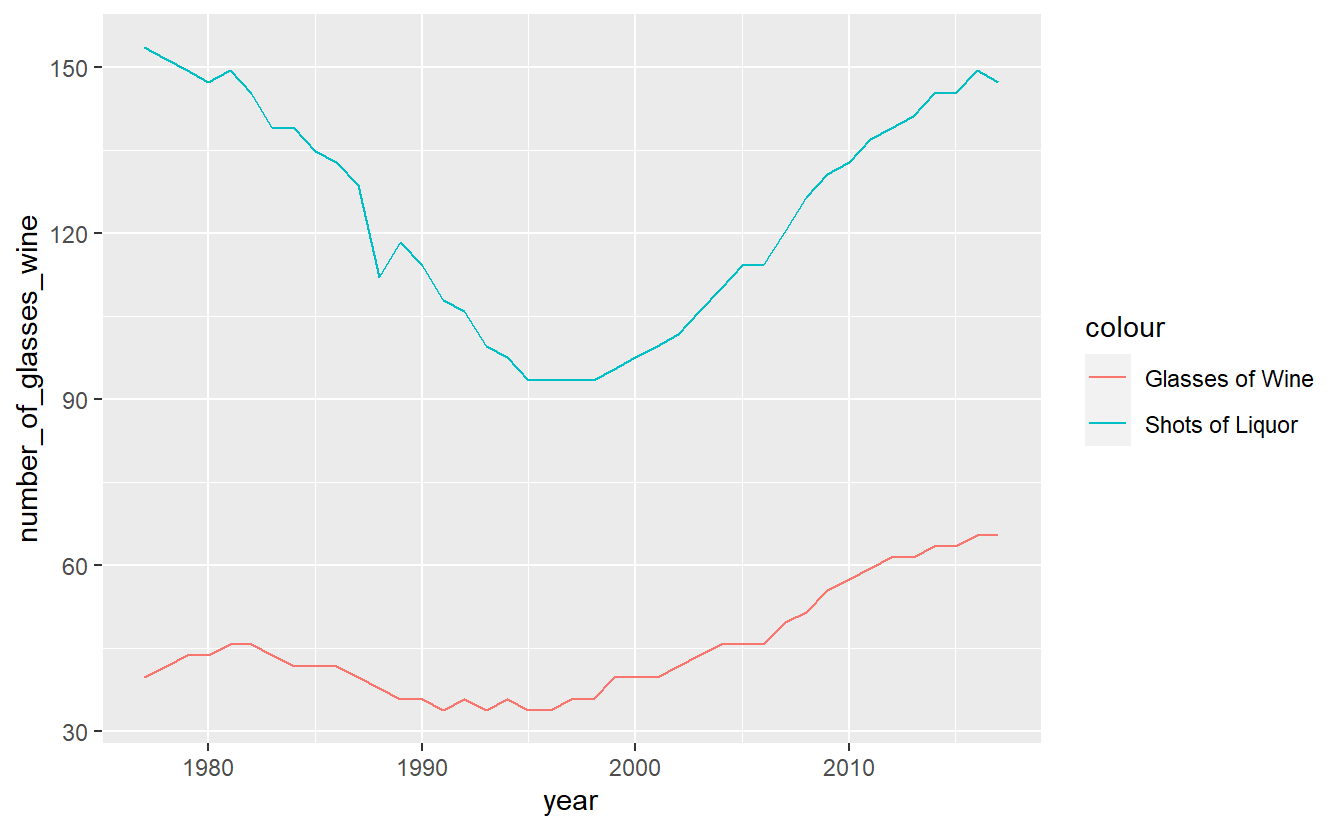
We can change the legend title by using the function labs() and changing the value color to what we want the legend title to be.
ggplot(penn_alcohol, aes(x = year,
y = number_of_glasses_wine,
color = "Glasses of Wine")) +
geom_line() +
geom_line(aes(x = year,
y = number_of_shots_liquor,
color = "Shots of Liquor")) +
labs(color = "Alcohol Type")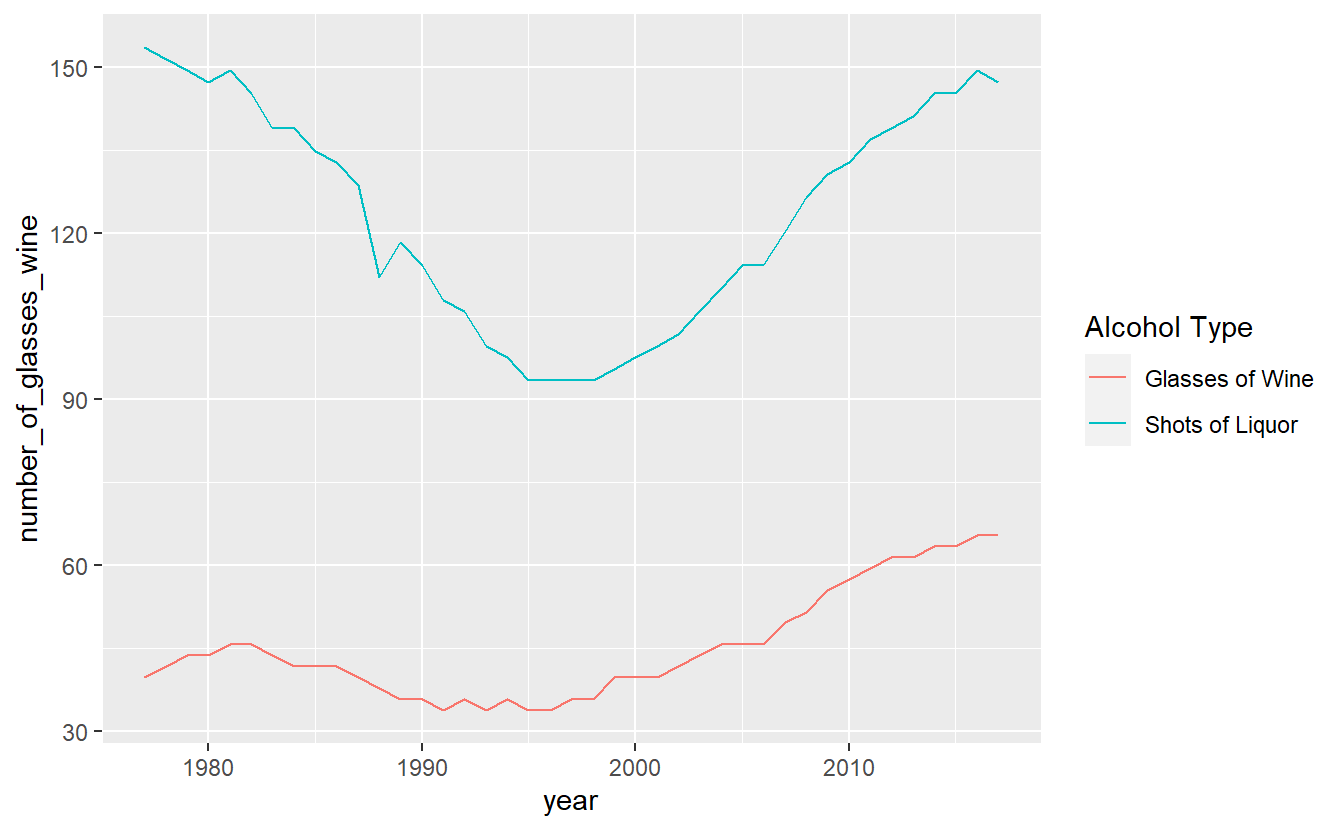
Finally, a useful option to move the legend from the side to the bottom is setting the theme() function to move the legend.position to “bottom”. This will allow the graph to be wider.
ggplot(penn_alcohol, aes(x = year,
y = number_of_glasses_wine,
color = "Glasses of Wine")) +
geom_line() +
geom_line(aes(x = year,
y = number_of_shots_liquor,
color = "Shots of Liquor")) +
labs(color = "Alcohol Type") +
theme(legend.position = "bottom")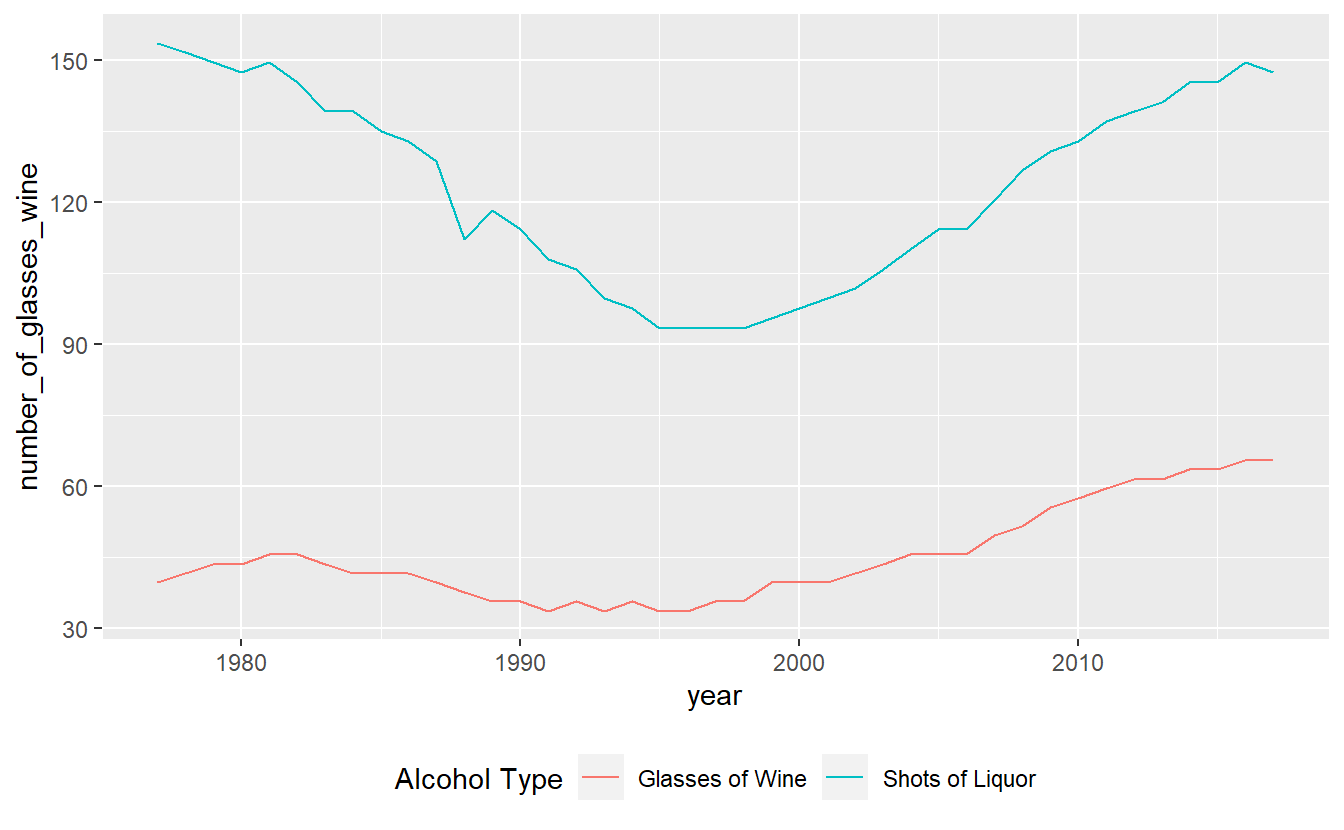
14.4 Scatter plots
Making a scatter plot simply requires changing the x-axis from year to another numerical variable and using geom_point(). Since our data has one row for every year for Pennsylvania, we can make a scatterplot comparing different drinks in each year. For this example, we’ll compare liquor to beer sales.
ggplot(penn_alcohol, aes(x = number_of_shots_liquor,
y = number_of_beers)) +
geom_point()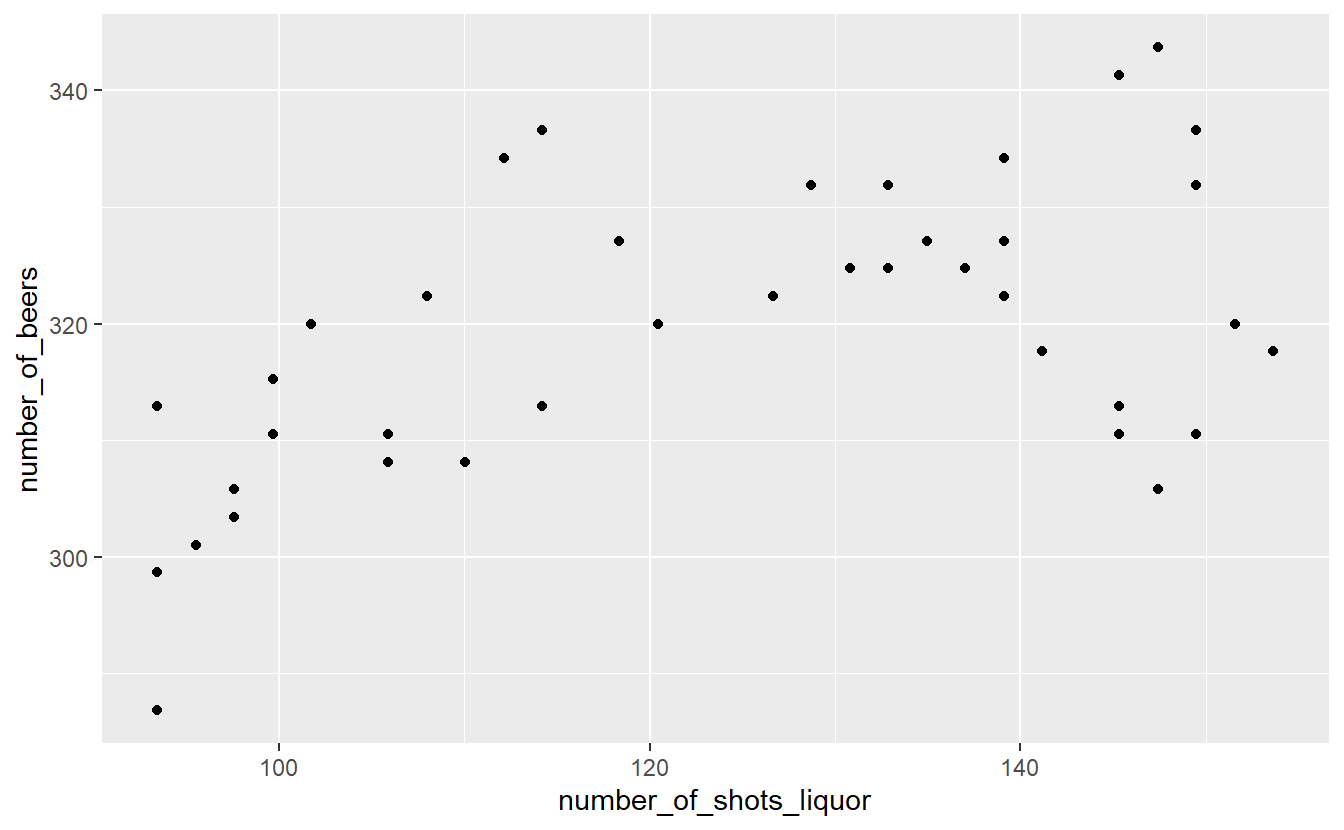
This graph shows us that when liquor consumption increases, beer consumption also tends to increase.
While scatterplots can help show the relationship between variables, we lose the information of how consumption changes over time.
14.5 Color blindness
Please keep in mind that some people are color blind so graphs (or maps, which we will learn about soon) will be hard to read for these people if we choose bad colors. A helpful site for choosing colors for graphs and maps is Color Brewer.
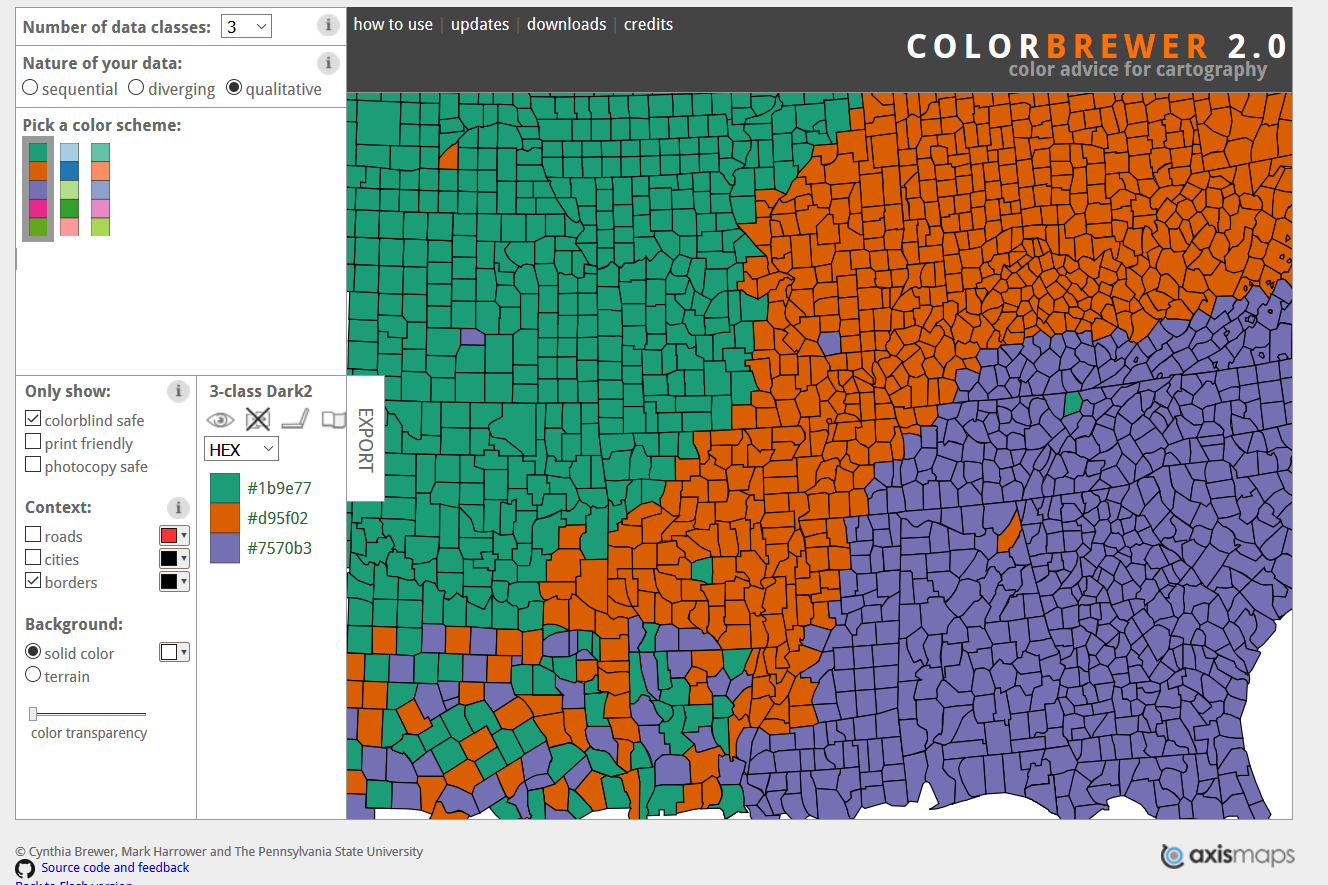
This site lets you select which type of colors you want (sequential and diverging, such as shades in a hotspot map, and qualitative, such as for data like what we used in this lesson). In the “Only show:” section you can set it to “colorblind safe” to restrict it to colors that allow people with color blindness to read your graph. To the right of this section it shows the HEX codes for each color. A HEX code is just a code that a computer can read and know exactly which color it is.
Let’s use an example of a color-blind friendly color from the “qualitative” section of ColorBrewer. We have three options on this page (we can change how many colors we want but it defaults to showing 3): green (HEX = #1b9e77), orange (HEX = #d95f02), and purple (HEX = #7570b3). We’ll use the orange and purple colors. To manually set colors in ggplot() we use scale_color_manual(values = c()) and include a vector of color names or HEX codes inside the c(). Doing that using the orange and purple HEX codes will change our graph colors to these two colors.
ggplot(penn_alcohol, aes(x = year,
y = number_of_glasses_wine,
color = "Glasses of Wine")) +
geom_line() +
geom_line(aes(x = year,
y = number_of_shots_liquor,
color = "Shots of Liquor")) +
labs(color = "Alcohol Type") +
theme(legend.position = "bottom") +
scale_color_manual(values = c("#7570b3", "#d95f02"))